
找寻有潜能的bilibiliTOP10UP主(1)
防喷表明:下列仅为本人学习之余的游戏项目,自己不主动授予以下几点一切使用价值,不保证 信息的精确性
热烈欢迎诸位友好的强调不正确
- 找寻有潜能的bilibiliTOP10UP主(1)
- 要求叙述
- 需求分析报告
- 辨别管理体系
- 第一次选择
- 第二次选择
- 获得所需数据信息
- 自己关心目录
- UP基本资料
- UP视頻信息内容
- 文章标题、时间、发布时间、播放量
- 视频弹幕、投币机、关注点赞、个人收藏、评价
- 数据预处理、统计分析
- 明确训炼数据信息及特点
- 导进数据信息
- 分析数据
- 特点遍布
- 特点平均值、中位值、标准偏差
- 有关系数矩阵
- 主成分分析法
- 聚类
- 聚类算法
- 辨别
- 训炼实体模型
- 有监管实体模型训炼
- 实体模型效果分析
- 实体模型展现图
- 改进方案
要求叙述
预测分析B站UP主是不是有潜质变成TOP10UP主或著名UP主
要求是自拟的,随意提的一个念头
需求分析报告
关键词:预测分析、归类
这一要求的或是相对比较易于明白的,大家必须搭建一个辨别管理体系,这一辨别管理体系可以根据给定的信息将其分到已经知道的种类中。
大家必须做的是
- 明确辨别管理体系
- 获得所需数据信息
- 数据预处理、统计分析
- 明确训炼模式及方式
- 训炼实体模型
- 评价指标体系
辨别管理体系
因为B站并沒有发布TOP10UP主选择的规范(即使有也当它沒有行吧),因此大家必须自身选择样版值
第一次选择
括弧内为特点权重值,权重值总数100%
| 粉絲人群相似性(16%) | 均值视頻文章标题篇幅(8%) | 均值视頻时间(12%) | 均值文章投稿时间范围(12%) | 均值视频弹幕占播放量比率(9%) | 均值投币机占播放量比率(12%) | 均值关注点赞占播放量比率(9%) | 均值个人收藏占播放量比率(10%) | 均值评价占播放量比率(12%) |
|---|
这一辨别管理体系就是我觉得可以较为客观性较为UP主间类型的辨别管理体系。
- 粉絲人群相似性:提前准备获得每一位UP主的用户目录,随后用Tanimoto得分测算相似性
- 均值视頻文章标题篇幅:文章标题长度很有可能有一些危害,给的权重值并不是许多
- 均值视頻时间:视頻时相貌一样更有可能是同一类UP
- 均值文章投稿时间范围:挑选时间点文章投稿一直是门风水玄学
- 均值视频弹幕占播放量比率:视频弹幕是视频播放的增香剂,好的视頻视频弹幕量一定许多,但刷视频弹幕相对性非常容易因此权重值减少
- 均值投币机占播放量比率:投币机是对高品质短视频的毫无疑问,与此同时刷投币机较为难,因此权重值高
- 均值关注点赞占播放量比率:关注点赞相对而言是相对比较很容易的,刷关注点赞也多,因此权重值低
- 均值个人收藏占播放量比率:个人收藏对于我自身来讲也是非常难进行的,即使他是高质量資源也很抵触个人收藏(很有可能这也是为什么呢么多下一次一定的缘故),因此权重值相对性减少
- 均值评价占播放量比率:也表明了视頻品质,与此同时出自于脸面不容易机刷评论,因此权重值高
但因为B站针对查询别人粉絲有数目限定,没法获得UP主的详细粉絲名册,因此粉絲人群相似性这一特点没法完成
第二次选择
| 均值视頻文章标题篇幅(10%) | 均值视頻时间(15%) | 均值文章投稿时间范围(15%) | 均值视频弹幕占播放量比率(10%) | 均值投币机占播放量比率(14%) | 均值关注点赞占播放量比率(10%) | 均值个人收藏占播放量比率(12%) | 均值评价占播放量比率(14%) |
|---|
获得所需数据信息
明确完辨别管理体系,大家下面明确必须什么数据信息
- 样版基本资料,及UP主的ID、呢称、称号
- 根据ID获得每一个UP的全部粉絲
- 根据ID获得每一个UP的视频的文章标题、时间、发布时间、播放量、视频弹幕数、投币机、关注点赞、个人收藏、评价
自己关心目录
-
要求URL
-
https://api.bilibili.com/x/relation/followings?
-
-
请求头主要参数
-
referer: https://space.bilibili.com/{vmid}/fans/follow cookie: {cookie}
-
-
带上主要参数
-
vmid: {vmid} pn: 2 ps: 20 order: desc order_type: attention
-
UP基本资料
-
要求URL
-
https://api.bilibili.com/x/space/acc/info?
-
-
带上主要参数
-
mid: {mid}
-
UP视頻信息内容
文章标题、时间、发布时间、播放量
-
要求URL
-
https://api.bilibili.com/x/space/arc/search?
-
-
请求头主要参数
-
referer: https://space.bilibili.com/{vmid}/fans/follow
-
-
带上主要参数
-
mid: {mid} ps: 1 tid: 0 pn: 1 order: pubdate jsonp: jsonp
-
视频弹幕、投币机、关注点赞、个人收藏、评价
-
要求URL
-
https://api.bilibili.com/x/web-interface/archive/stat?
-
-
请求头主要参数
-
referer: https://space.bilibili.com/{vmid}/fans/follow
-
-
带上主要参数
-
aid: {aid}
-
数据预处理、统计分析
获得到的短视频数据信息中有已被删掉的短视频数据信息,这种信息的播放量为‘–’,不可记入总视頻量,与此同时因为需规定均值实际操作,播放量为零的短视频必须做特别解决。
视頻文章标题必须统计字数
视頻时间得到的文件格式为‘HH:MM’,必须统一成分秒
视频上传時间为时间格式文件格式,必须统一成钟头
必须对每一位UP加上标识
明确训炼数据信息及特点
下面的使用都是在MATLAB中进行
导进数据信息
clear,clc
[data,name] = xlsread('bilibiliUP','Sheet1','B2:J149');
save data name data
分析数据
样版数量为14八个,特点项8项
特点遍布
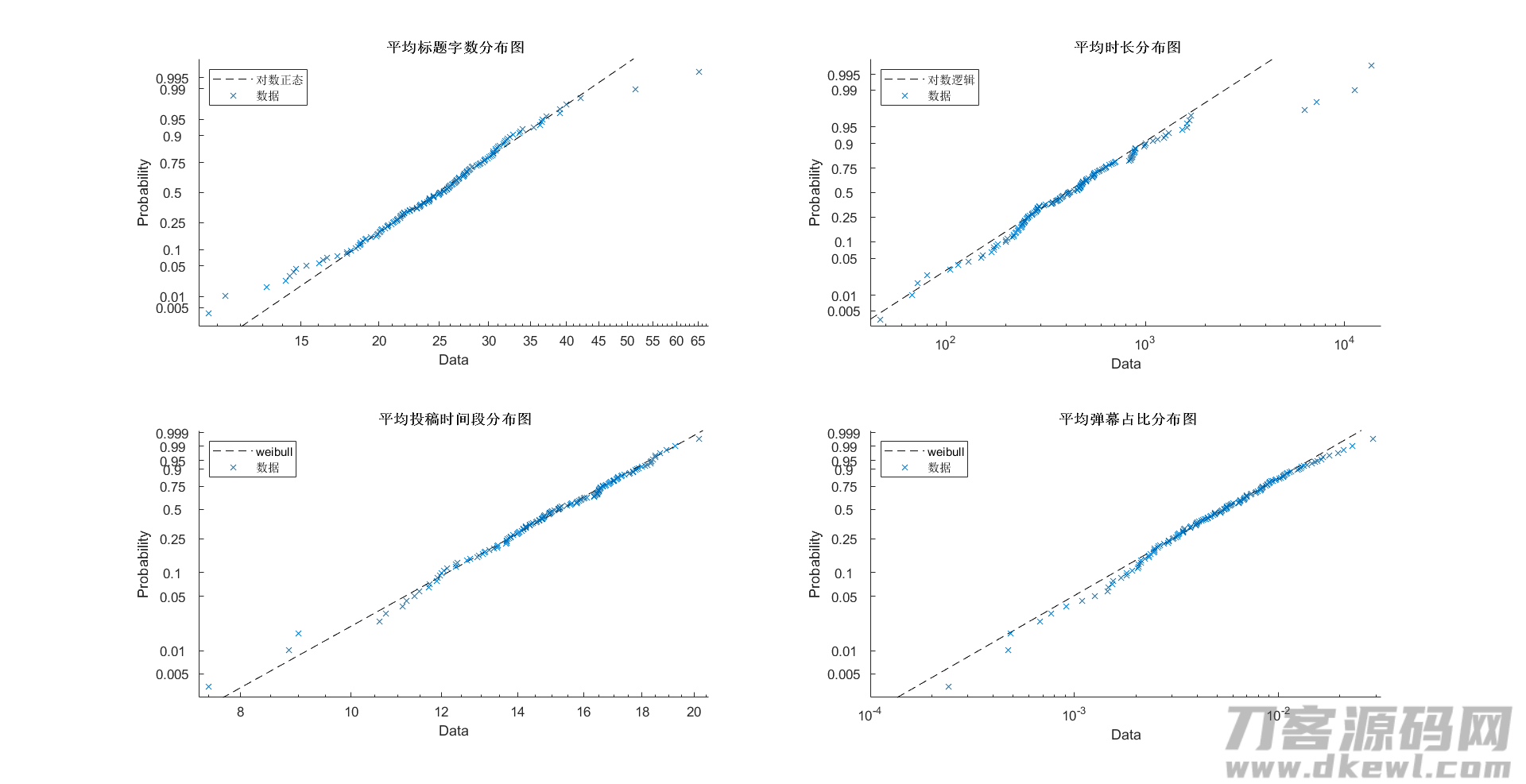
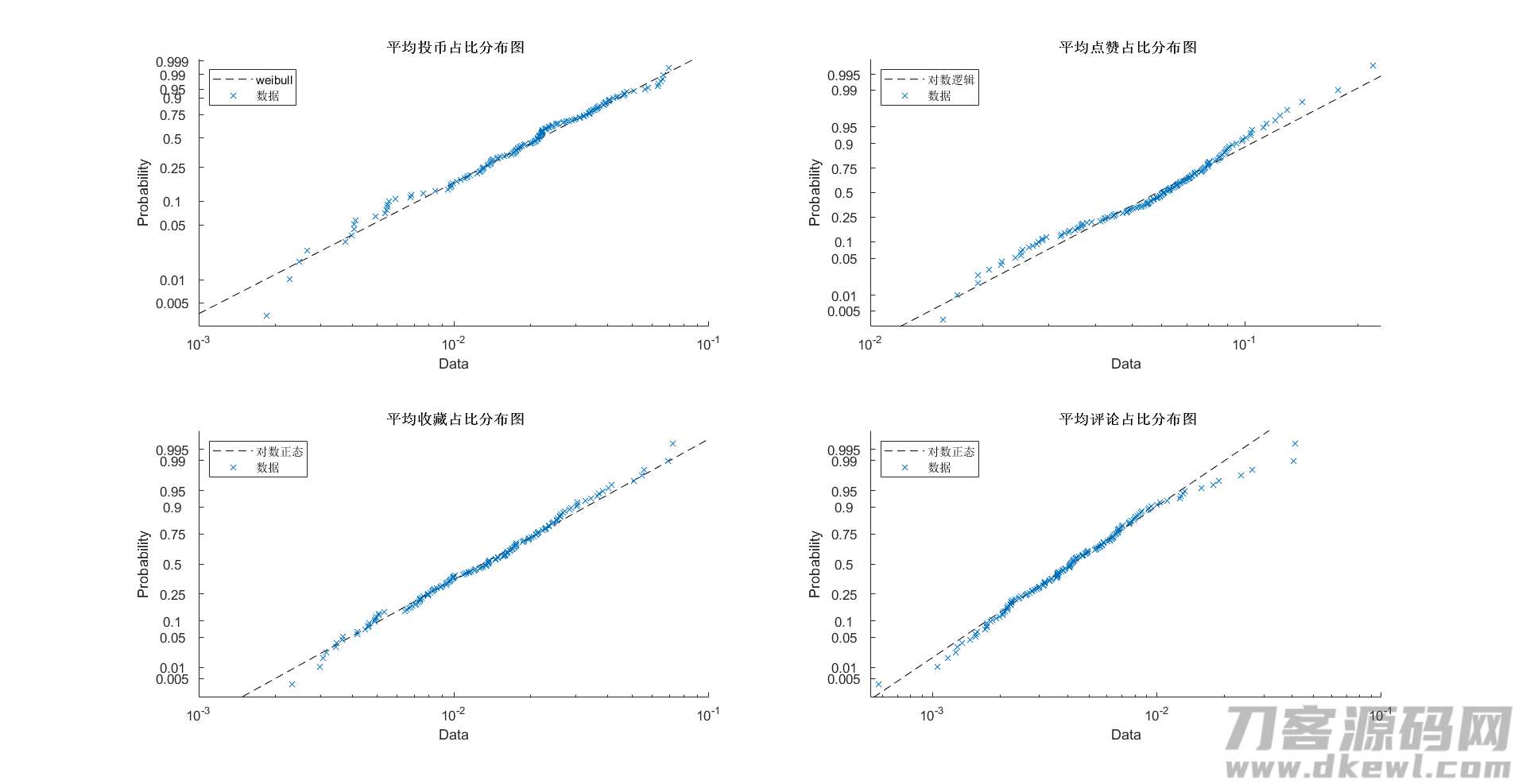
特点平均值、中位值、标准偏差
| 均值视頻文章标题篇幅(个) | 均值视頻时间(s) | 均值文章投稿时间范围(h) | 均值视频弹幕占播放量比率(%) | 均值投币机占播放量比率(%) | 均值关注点赞占播放量比率(%) | 均值个人收藏占播放量比率(%) | 均值评价占播放量比率(%) | |
|---|---|---|---|---|---|---|---|---|
| 平均值 | 25.5496 | 739.2298 | 15.0893 | 0.64 | 2.37 | 6.33 | 1.63 | 0.56 |
| 中位值 | 27.0743 | 414.5715 | 15.2024 | 0.54 | 2.14 | 6.06 | 1.36 | 0.41 |
| 标准偏差 | 7.0943 | 1.5957e 03 | 2.2214 | 4.7169e-03 | 1.4920e-02 | 2.9482e-02 | 1.2083e-02 | 5.7272e-03 |
有关系数矩阵
因为想要做下聚类,因此先向特点间关联性开展剖析
| 有关系数矩阵 | |||||||
|---|---|---|---|---|---|---|---|
| 1 | 0.0184325288466795 | -0.0249488481946810 | 0.000556029951779419 | -0.0781882042420524 | -0.168742474288945 | 0.0918842200982381 | 0.211218436765012 |
| 0.0184325288466795 | 1 | -0.0684400833088982 | 0.135256877104381 | -0.0839986211337289 | -0.231039187955712 | 0.161255474364964 | -0.0238979157736475 |
| -0.0249488481946810 | -0.0684400833088982 | 1 | 0.0642875823784235 | 0.182932469005339 | 0.216237989286477 | -0.0167989352674504 | -0.124649717355339 |
| 0.000556029951779419 | 0.135256877104381 | 0.0642875823784235 | 1 | 0.418871812486625 | -0.0442827567357434 | -0.0158181841190108 | 0.0996439284969066 |
| -0.0781882042420524 | -0.0839986211337289 | 0.182932469005339 | 0.418871812486625 | 1 | 0.468509412567601 | 0.438604301439134 | 0.241896824716753 |
| -0.168742474288945 | -0.231039187955712 | 0.216237989286477 | -0.0442827567357434 | 0.468509412567601 | 1 | 0.183186223938856 | 0.0503927120668548 |
| 0.0918842200982381 | 0.161255474364964 | -0.0167989352674504 | -0.0158181841190108 | 0.438604301439134 | 0.183186223938856 | 1 | 0.357856402521907 |
| 0.211218436765012 | -0.0238979157736475 | -0.124649717355339 | 0.0996439284969066 | 0.241896824716753 | 0.0503927120668548 | 0.357856402521907 | 1 |
较大相关系数r为0.47,归属于一般有关,这儿本人仍挑选开展主成分分析法
主成分分析法
| 增长率(%) | 荷载引流矩阵 | |||||||
|---|---|---|---|---|---|---|---|---|
| 25.1275 | -0.0154356012464888 | 0.439271317949718 | -0.239468930154721 | 0.640874181590308 | 0.299234983162774 | -0.489223750723536 | 0.0908810289215616 | 0.0399568700489856 |
| 18.6910 | -0.0633151967720804 | 0.392258362039291 | 0.504163254738602 | -0.411223722446849 | 0.444807070009181 | -0.0650455225958284 | 0.440099753219734 | 0.151878186756074 |
| 14.8629 | 0.178975010961490 | -0.393567647425860 | 0.168327298137570 | 0.380362735131868 | 0.659830736056726 | 0.448429308073384 | -0.0501509982524432 | -0.0328937010028770 |
| 12.4349 | 0.269286890707300 | 0.113144944244625 | 0.678576159768060 | 0.337839313324345 | -0.359229553698078 | -0.0556086435211860 | -0.0116149200092179 | -0.455860379941969 |
| 11.5216 | 0.625773896426006 | -0.0714169658824892 | 0.155677911835697 | 0.0140278224639614 | -0.112535587324820 | -0.184136256454763 | -0.169887284588042 | 0.709536571769867 |
| 7.6773 | 0.431907250553736 | -0.415984327691833 | -0.237474739608985 | -0.140210810209029 | 0.0404217529290391 | -0.345760241577645 | 0.589026077373038 | -0.310200032544974 |
| 6.4894 | 0.449395895969865 | 0.325883099539835 | -0.181948722076682 | -0.358695083065022 | 0.299349431999138 | -0.0494929449168077 | -0.521984313795124 | -0.406876856255649 |
| 3.1955 | 0.333334561923556 | 0.448479293459293 | -0.293153813734111 | 0.113340671631467 | -0.210414742505219 | 0.629557129219618 | 0.383564575615655 | 0.0350827640124736 |
剖析得:前六项总计增长率达90.3%,故挑选前六项开展剖析
对新数据再度开展相关系数r剖析
| 有关系数矩阵 | |||||
|---|---|---|---|---|---|
| 1 | 0.182007545883040 | -0.0713354084624925 | -0.151681329692816 | 0.0614584785271987 | -0.125737466947417 |
| 0.182007545883040 | 1 | 0.324008369791875 | 0.0885939787345643 | 0.0591884996936010 | -0.133187717940026 |
| -0.0713354084624925 | 0.324008369791875 | 1 | -0.0852536338605460 | -0.00112597217476600 | 0.00576904941809119 |
| -0.151681329692816 | 0.0885939787345643 | -0.0852536338605460 | 1 | -0.174500701145123 | -0.256700669541367 |
| 0.0614584785271987 | 0.0591884996936010 | -0.00112597217476600 | -0.174500701145123 | 1 | 0.110149618536761 |
| -0.125737466947417 | -0.133187717940026 | 0.00576904941809119 | -0.256700669541367 | 0.110149618536761 | 1 |
各特点间相关系数r低,合乎预估
聚类
聚类算法
clear
clc
load data
Y = pdist(clearData, 'mahalanobis');
Z = linkage(Y,'average');
C = cophenet(Z,Y) %测算cophenet相关系数r,取较大就可以
figure
T = cluster(Z,6);
dendrogram(Z, 0, 'Orientation','left','ColorThreshold','default','Labels', name) %转化成谱系图
title('{\bf 谱系图}')
% LDA特征提取
[YY, WW, lambda] = LDA(clearData, T);
% Tsne
mappedX = tsne(clearData, [], 3, 6, 30);
%制图
figure
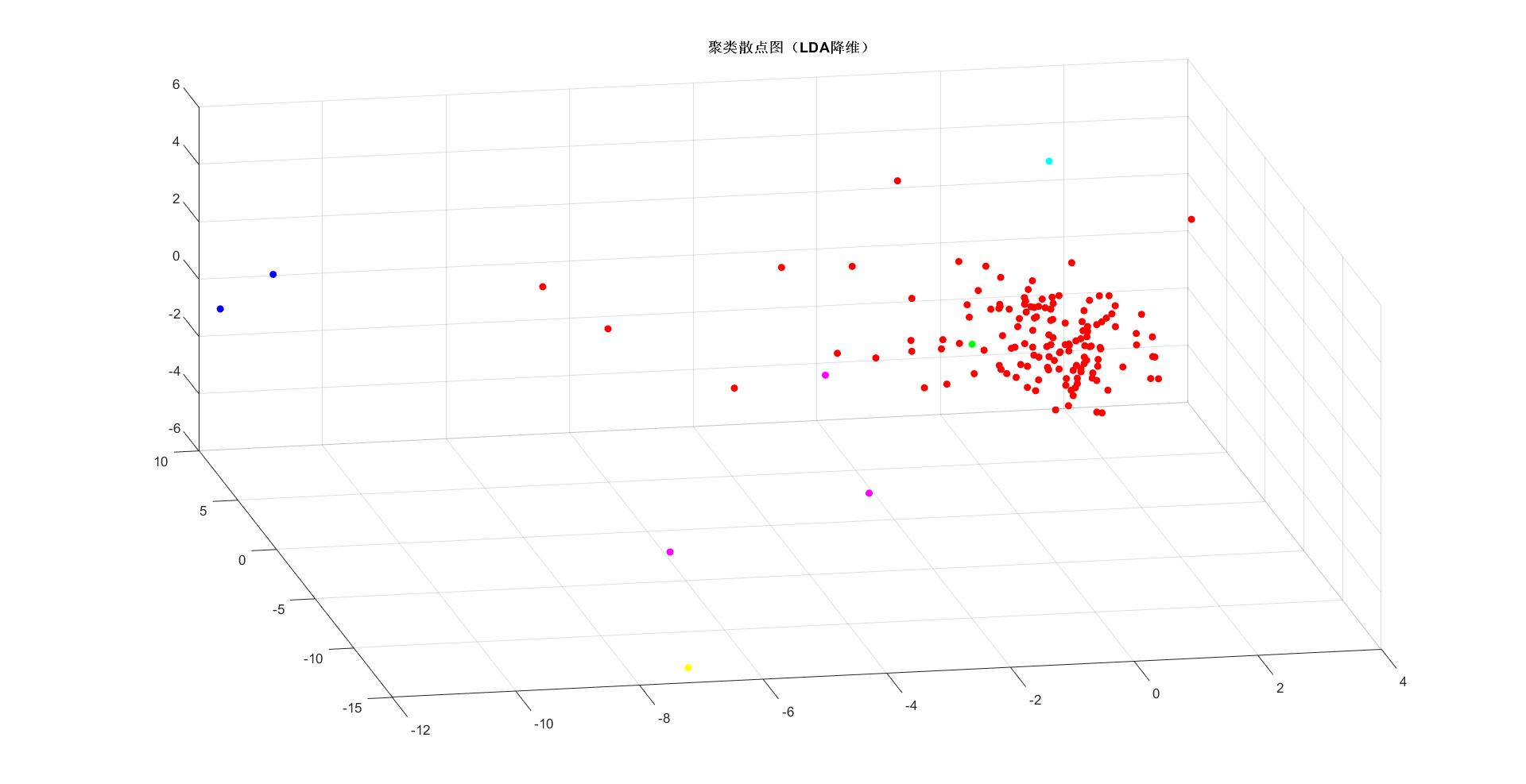
scatter3(YY(:,1), YY(:,2), YY(:,3), 30, colorSet(T), 'filled')
title('{\bf 聚类算法散点图(LDA特征提取)}')
figure
scatter3(mappedX(:,1), mappedX(:,2), mappedX(:,3), 30, colorSet(T), 'filled')
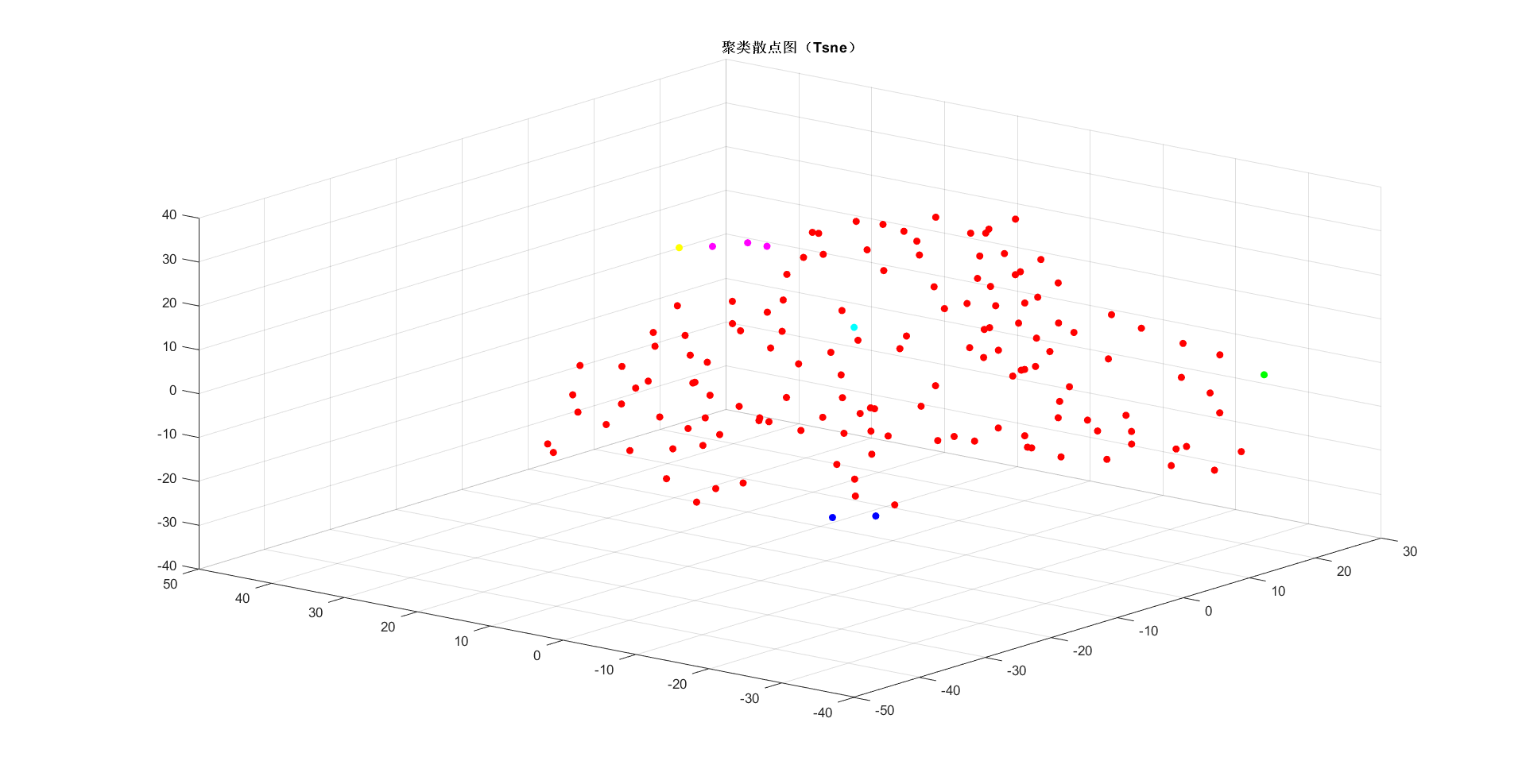
title('{\bf 聚类算法散点图(Tsne)}')
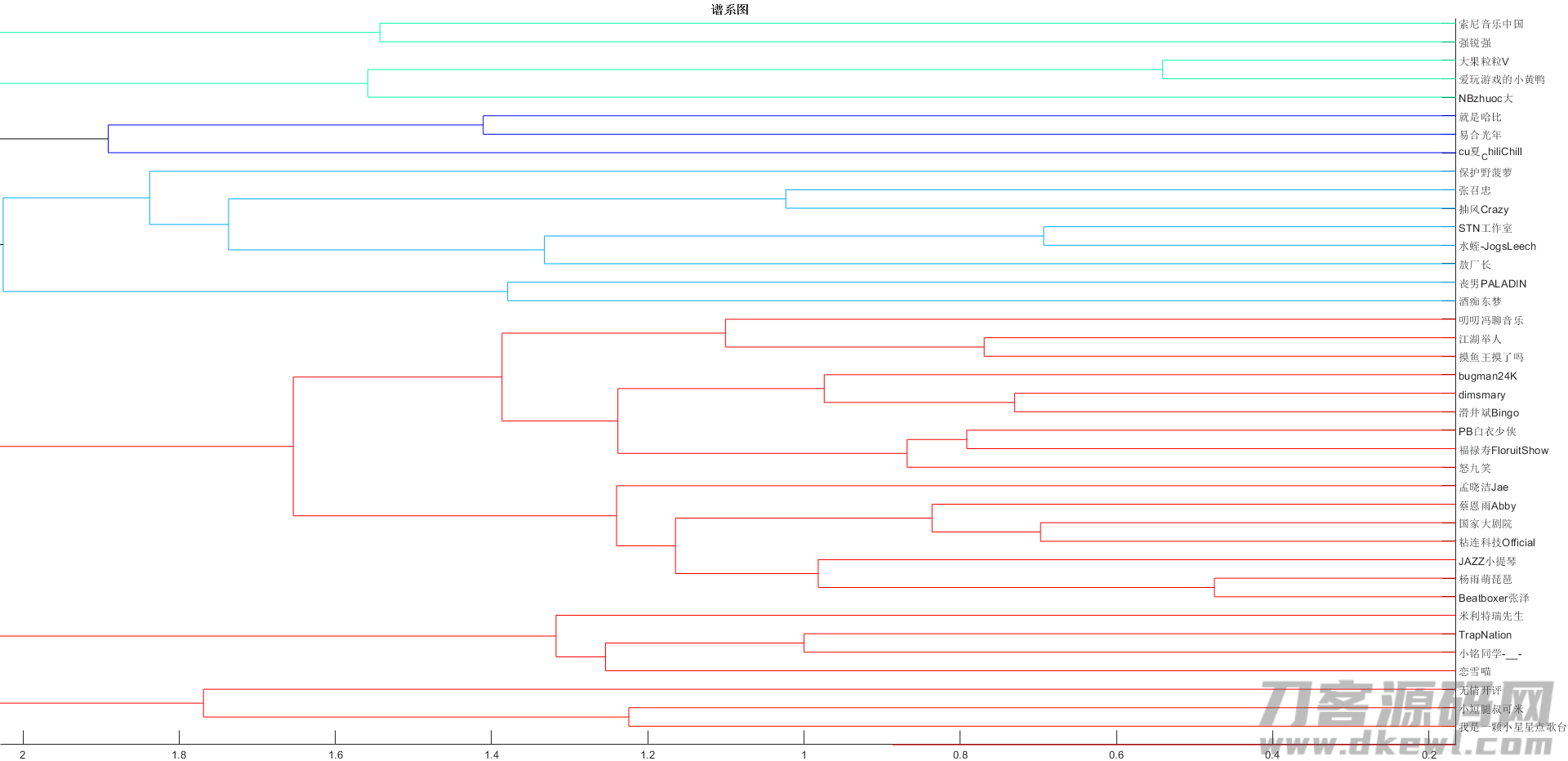
详细谱系图见 bilibiliUP谱系图免费下载——登陆密码:6634_
辨别
clear
clc
load data
%转化成训炼检测集
indices = crossvalind('Kfold', size(clearData,1), 30);
tests = (indices == 1);
train = ~tests;
trainData = clearData(train, :);
trainName = name(train,:);
testData = clearData(tests,:);
testName = name(tests,:);
%聚类算法
% trainData = zscore(trainData);%对提取样版再次规范化
Y = pdist(trainData, 'euclidean');
Z = linkage(Y,'ward');
T = cluster(Z,6);%分六类
%辨别
[class,err] = classify(testData,trainData,T,'diagLinear');
testName,class
%SVM
svmModel = fitcecoc(trainData, T);
classification = predict(svmModel, testData);
classification
% LDA特征提取
trainAndTest = [T,trainData];
trainAndTest = [trainAndTest;[class,testData];[classification,testData]];
trainLen = size(trainData, 1);
testLen = size(testData, 1);
[YY, WW, lambda] = LDA(trainAndTest(:,2:end), trainAndTest(:,1));
% 制图
figure
scatter(YY(1:trainLen,1), YY(1:trainLen,2), 30, colorSet(trainAndTest(1:trainLen,1)), 'filled')
hold on
s2 = scatter(YY(trainLen 1:trainLen testLen,1), YY(trainLen 1:trainLen testLen,2), 50, colorSet(trainAndTest(trainLen 1:trainLen testLen,1)), '^');
hold on
s3 = scatter(YY(trainLen testLen 1:end,1), YY(trainLen testLen 1:end,2), 50, colorSet(trainAndTest(trainLen testLen 1:end,1)), 'v');
legend([s2,s3],'对角性间距预测分析','SVM预测分析')
title('{\bf 根据聚类算法的辨别(LDA特征提取)}')
text(YY(trainLen testLen 1:end,1),YY(trainLen testLen 1:end,2),testName(:,1))
hold off
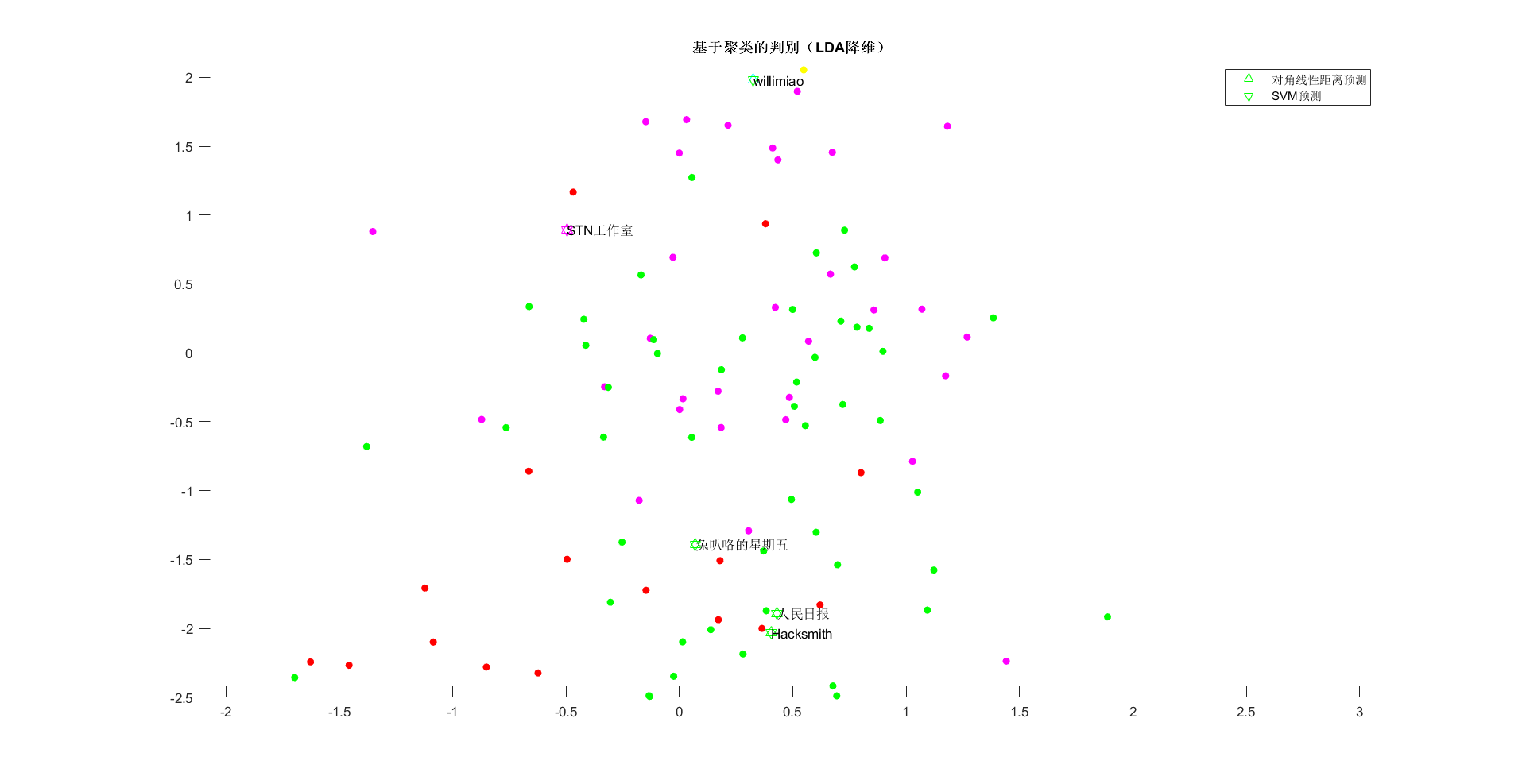
应用聚类算法对信息实现了探寻,并试着开展辨别,但并沒有可以了解聚类算法后的UP主间的关联,嘿嘿。下一步提前准备进到主题风格,运用已经知道标识开展实体模型训炼。
训炼实体模型
有监管实体模型训炼
由于下面的练习都已经知道标识,因此预置的特点权重值在练习中没有意义,故挑选未权重计算的规范化数据信息。
clear,clc
load data
ct1 = 0;
ct2 = 0;
rR1 = zeros(2,2);%混淆矩阵
rR2 = zeros(2,2);
times = 4;
clearData = zscore(data);
indices = crossvalind('Kfold', size(clearData,1), times);
i = 1;
for i = 1 : times
tests = (indices == i);
train = ~tests;
trainData = clearData(train, :);
trainName = name(train,:);
trainScore = score(train,:);
testData = clearData(tests,:);
testName = name(tests,:);
testScore = score(tests,:);
T = trainScore;
%辨别
[class,err] = classify(testData,trainData,T,'diagLinear');
%SVM
t = templateSVM('Standardize',true,'BoxConstraint',2);
svmModel = fitcecoc(trainData, T, 'Learners',t);
classification = predict(svmModel, testData);
% 测算
[m1,rR1] = mre(testScore, class, rR1);
ct1 = ct1 m1;
[m2,rR2] = mre(testScore, classification, rR2);
ct2 = ct2 m2;
end
'对角性间距辨别MRE、混淆矩阵、准确度、均方误差:'
ct1/times
rR1
right1 = rR1./sum(rR1,1);
recall1 = rR1./sum(rR1,2);
right1(1),recall1(1)
'svm算法MRE、混淆矩阵、准确度、均方误差:'
ct2/times
rR2
right2 = rR2./sum(rR2,1);
recall2 = rR2./sum(rR2,2);
right2(1),recall2(1)
根据对角性和svm算法的较为,及其在不一样标识下的主要表现,目前以下结果(评定规范为MRE、混淆矩阵、精准率、均方误差):
-
在标识为2类即【TOP10/非TOP10】时,开展五十层交叉验证
- 顶角线性模型
- MRE:0.4707
- 混淆矩阵 [103,30;3,12]
- 精准率 [0.9717;0.2857](非TOP10;TOP10)
- 均方误差 [0.7744;0.8000]
- SVM
- MRE:0.3372
- 混淆矩阵 [130,3;14,1]
- 精准率 [0.9028;0.2500](非TOP10;TOP10)
- 均方误差 [0.9774;0.0667]
- 顶角线性模型
-
在标识为3类即【TOP10/著名/一般】时,开展五十层交叉验证
- 顶角线性模型
- MRE:0.8091
- 混淆矩阵 [60,17,10;16,17,13;2,5,8]
- 精准率 [0.7692;0.4359;0.2581](一般;著名;TOP10)
- 均方误差 [0.6897;0.3696;0.5333]
- SVM
- MRE:0.6508
- 混淆矩阵 [75,11,1;26,19,1;6,5,4]
- 精准率 [0.7009;0.5429;0.6667](一般;著名;TOP10)
- 均方误差 [0.8621;0.4130;0.2667]
- 顶角线性模型
-
在标识为4类即【TOP10 著名/TOP10/著名/一般】时,开展五十层交叉验证
- 顶角线性模型
- MRE:1.1934
- 混淆矩阵 [56,11,13,7;10,13,11,12;0,2,3,1;0,3,1,5]
- 精准率 [0.8485;0.4483;0.1071;0.2000](一般;著名;TOP10;TOP10 著名)
- 均方误差 [0.6437;0.2826;0.5000;0.5556]
- SVM
- MRE:0.7737
- 混淆矩阵 [75,9,2,1;25,18,2,1;1,4,1,0;1,4,2,2]
- 精准率 [0.7353;0.5143;0.1429;0.5000](一般;著名;TOP10;TOP10 著名)
- 均方误差 [0.8621;0.3913;0.1667;0.2222]
- 顶角线性模型
实体模型效果分析
历经剖析,在目前样版集下,在2类预测分析时,对角性预测分析在预测分析非TOP10时精准度高做到97%,在预测分析TOP10时均方误差较高做到80%,表明当此模型预测为非TOP10时,有97%概率预测分析恰当,此模型预测为TOP10的全部UP中,有80%的UP可以变成TOP10。
与此同时剖析发觉,在目前样版集下,多种类型预比测,二种形式的准确率或均方误差都较低,剖析混淆矩阵后觉得缘故是样版集中化标识占有率不平衡造成 ,目前样版集下有样版148份,在其中TOP10 著名9份、TOP106份、著名46份,占较为低,造成 训炼实体模型欠拟合。
实体模型展现图
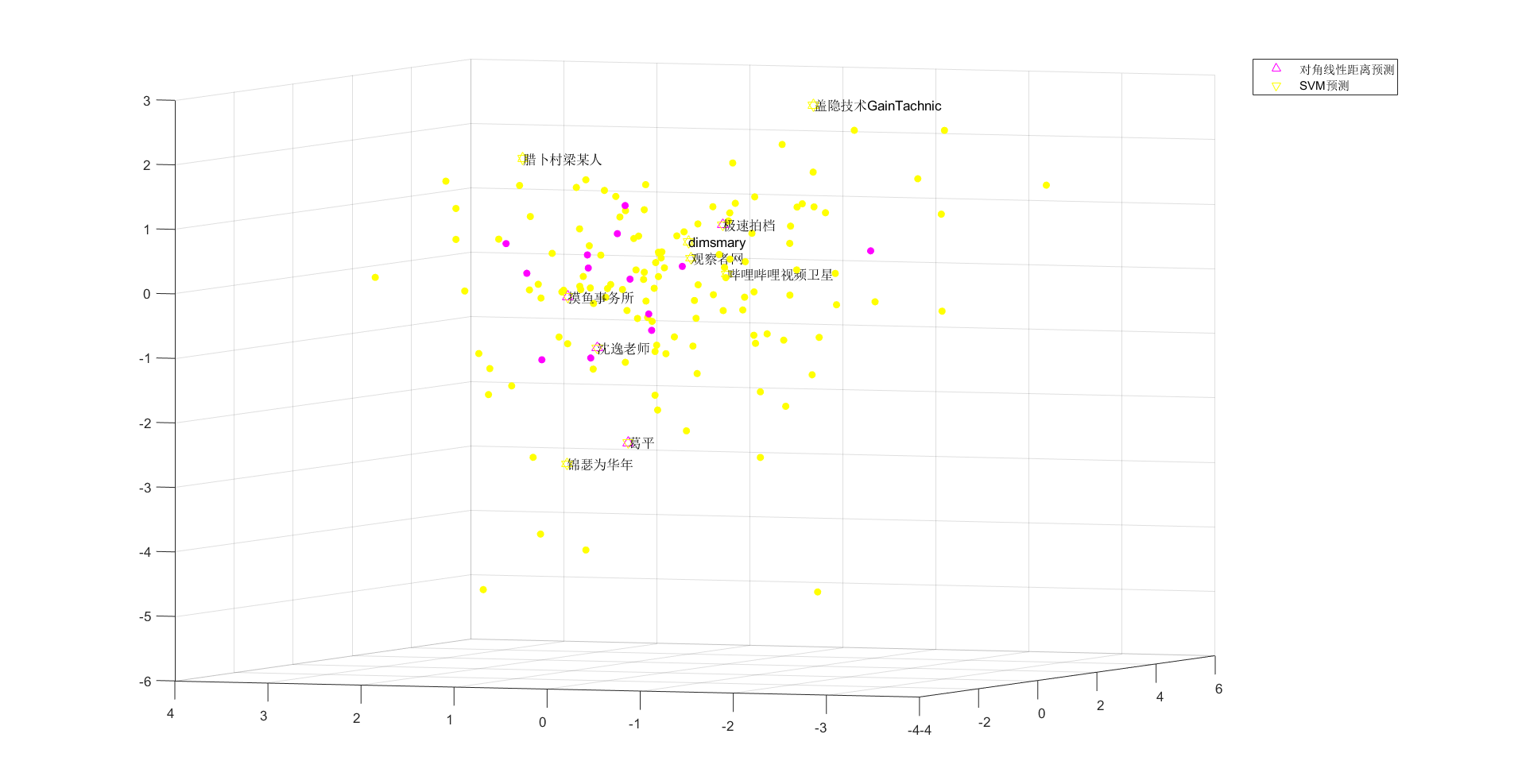
改进方案
历经剖析,现阶段关键现象为数据内不一样标签数据量占有率比较严重失调,处理方位有两个:提升信息量占较为少的标识的信息量或是是降低占有率过大的标识的信息量。处于现阶段标识数为4,样本量148,挑选提升信息量是比较很容易的方法。
因为B站有反爬对策,而TOP10UP主视頻数据信息相对性较多,均值每个人数据信息必须0.5天抓取,预估提升TOP10UP主总数到150位,总样版总数抵达300个上下,更快必须一个月時间可以抓取结束,改善进行之后将内容连接升级在文中。













